薬理ゲノミクスのための化合物・糖鎖データベースの開発
本研究では、ゲノムレベルで解析可能な化合物(特に糖鎖)構造のデータベースを開発し、遺伝子発現データ解析など薬理ゲノミクスへと応用できる仕組みを構築することを目的とする。我々はKEGGプロジェクトにおいて、化学反応情報データベースLIGANDを構築しているが、この中でも特に糖鎖構造データベースGLYCANおよび周辺技術の開発を中心に進めている。
1.糖鎖構造情報データベース GLYCAN
GLYCANはこれまでに明らかにされてきた糖鎖構造を文献から収集しデータベース化したものである。従来からあるCarbBankの活動を引き継ぐ形で進めているが、より構造解析を行ないやすい形で構築している。また、構造入力・構造検索のためのフォーマットKCFを開発し、新規データの入力、構造検索に応用している。
|
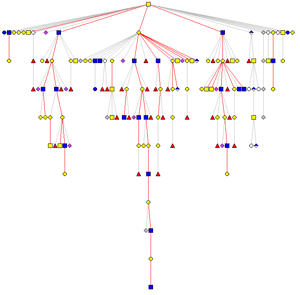
2.糖鎖構造マップ
GLYCANでは一つのエントリーが一つの糖鎖構造に対応しており、構造間の類似度や同じルート(根)を持つ構造をまとめてみることはできない。糖鎖構造マップでは、同じルートを持つ構造を一つにまとめた形で表現している(右図)。ここでは、単糖間のグリコシル結合は糖転移酵素に対応しており、ゲノムレベルでの解析に応用できるようになっている。例えば、糖鎖構造の種間比較を行える。また、マイクロアレイデータから発現している遺伝子の情報を抽出し、糖鎖構造マップに色づければ、発現している糖鎖構造およびその合成経路が予測できると期待できる。
|
 |
3.糖鎖構造入力ツール KegDraw
糖鎖構造入力ツールはこれまで一般的なものがなかった。そこで様々なプラットフォームで利用できるように Javaアプリケーションで糖鎖構造入力ツールKegDrawを開発している。KegDrawでは糖鎖構造だけでなく、化合物構造の入力もできる。また、サーバー側のデータベースとの連携機能も持たせ、新規データの入力や構造検索をそのまま行えるようにしている。
|





{kind=link}